
개인 공부용으로 번역한 거라 잘못 번역된 내용이 있을 수 있습니다.
또한 원작자의 동의 없이 올려서 언제든 글이 내려갈 수 있습니다.
원문 : http://rastergrid.com/blog/2010/10/hierarchical-z-map-based-occlusion-culling/
Hierarchical-Z 는 현대 GPU 의 잘알려진 표준 기능이다. 이것은 큰 그룹으로 입력되는 Fragments를 제외시키므로써 on-chip 메모리안에 있는 축소되고 압축된 버젼의 Depth buffer를 사용하여 Depth testing 의 속도를 높혀준다. 이 글에서 제시된 기술은 다음과 같은 기본 아이디어를 사용한다. 많은 수의 개별 오브젝트들에 batched 된 Occlusion culling를 CPU 개입없이(전통적인 방식에서는 CPU 개입) 지오메트리 쉐이더를 사용하여 가능케 해준다.이 글은 또한 OpenGL 4.0 형태로 구현 레퍼런스 제공한다. Mountains 데모는 천개의 오브젝트 인스턴스를 컬링하는 것을 이 기술을 사용하여 보여준다.Introduction오클루전 컬링은 눈에 보일 수 있는지를 판단하는 알고리즘을 사용하여, View volume 안에 있는 오브젝트들을 대상으로 Occlusion으로 인해 스크린에 보여지지 않는지 여부를 판단한다. 즉, 이런 오브젝트는 카메라에 더 가까이 있는 오브젝트 때문에 가려졌다는 뜻이다.여러세대 동안 GPU는 하드웨어 가속을 사용해 Occlusion queries 형태로 Occlusion culling을 가능케 하였다. OpenGL은 ARB_occlusion_query 확장을 통해 이 기능을 제공하였다. Occlusion queries는 아주 간단하다.(Occlusion query가 켜진 상태로 오브젝트 하나를 그리면, query는 depth test를 pass한 samples 개수를 돌려준다. 혹은 true or false로 리턴 가능하며, 어떠한 오브젝트의 samples가 depth test를 pass한 한지 여부로 결정된다. 이기능은 OpenGL의 ARB_occlusion_query2 확장임)그래서 실제로 occlusion query를 사용하여 Occlusion culling을 수행하는것은 간단히 아래와 같다.1. Occlusion query가 켜져있는 채로 오브젝트를 그린다.2. 만약 query 결과가 object가 visible 한 상태면, 오브젝트를 그린다.첫째로, 이것은 오브젝트가 visible한지 아닌지를 판단하기 위해서 오브젝트를 그려봐야하기 때문에 바보같이 들릴 수 있다. 실제로는 occlusion query는 많은양의 GPU 작업을 절약할 수 있다. 당신이 몇천개의 삼각형을 가지고 있는 복잡한 오브젝트를 갖고 있다고 생각해보자. 만약 당신이 occlusion query를 사용해 visibility 여부를 체크하고 싶으면, 간단한 것을 렌더링 할 것이다. (예를 들면 오브젝트의 바운드박스 같은.. 바운드 박스가 visible이라면)오클루젼 쿼리가 passed 된 samples를 돌려줬다면, 오브젝트는 "아마 보일 것"이다. 이런 방법으로 불필요한 많은 양의 geometry 처리로 부터 GPU 작업을 절약할 수 있다.나는 "아마 보일 것"이라는 말을 쓴 것에 언급하고 싶다. Occlusion query는 정확한 결과 보다는 오브젝트가 visible 한지 아닌지 대략적인 추정치를 제공하기 때문이다. 이것은 바운드박스가 원본 오브젝트보다 스크린영역에서 다른(더 큰)영역을 차지하고 있기 때문이다. 그래서 우리가 오클루젼 컬링 알고리즘으로 부터 추측할 수 있는 것은 아래와 같다. 오브젝트는 보이지 않거나 혹은 오브젝트는 "아마 보일 것" 이다. 이 가능성이 더 클 수록 오클루젼 컬링의 효과는 더 크다.우리는 항상 오클루젼 컬링 알고리즘이 가능한 효과적이기를 원하지만, 보통 우리는 효과적임과 효율 사이에 트레이드 오프를 만들어야 합니다. 위에 예제에서 만약 우리가 100%의 효과적임을 바란다면, 우리는 모든 오브젝트를 그려야 할 것입니다. 그리고 그것은 대부분의 오클루젼 컬링의 목표에 도달하지 못하게 합니다. 이 글에서 제시된 알고리즘은 다소 실제보다 작은 예제이지만 더 많은 데이터 세트에 오클루젼 컬링을 가능케 해줍니다.
Motivation하드웨어 가속된 오클루젼 쿼리가 가시성 판별에 강력한 툴이긴 하지만, 오클루젼 쿼리와 오클루젼 쿼리 결과를 기반으로 오브젝트를 그리는것에 상당한 비용이 든다. (오클루젼 쿼리의 비동기 특성을 고려함). 가장 고지식한 오클루젼 쿼리의 사용은 그려야하는 오브젝트 바로전에 쿼리를실행하는 것이다. 이것은 가능한 아이디어 처럼 보이지만, 실전에서는 CPU가 쿼리 결과가 사용가능해질 때까지 stalled되고 Empty GPU Cycles 을 포함하기 때문에 수용할 수 없을 정도의 성능이라서 잘 사용하지 않는다. 이것을 해결하기 위해서 어플리케이션은 쿼리 샐행과 쿼리 결과를 기반으로 하는 오브젝트 렌더링 사이에 시간을 채워야 한다. 이것을 수행할 기술이 있지만, 구현의 복잡도가 올라감으로써 비용이 발생합니다.앞서 언급한 문제는 OpenGL 3(NV_conditional_render extention)에서 소개된 Conditional Rendering 을 사용하여 어느정도 해결되었다. 그러나 이 확장은 쿼리 결과가 아직 사용가능하지 않은 상태이면, 우리가 그것이 보이는지 안보이는지 여부에 관계없이 그냥 오브젝트를 그린다. 이것은 렌더링 파이프라인의 stalling을 피해게 할 수 있고, 이 확장(역주: 오클루젼 쿼리 확장을 말하는 듯)을 사용할 수 없는 경우는 소프트웨어에서 완료 될 수 있습니다. 그러나 이것은 오클루젼 컬링의 목적을 희석시킵니다.오클루젼 쿼리를 사용할때 또 다른 약점은 오브젝트의 가시성을 결정하기 위해서 여전히 CPU의 개입이 필요한 것이다.적절한 batching이 렌더러의 가장 중요한 측면중 하나인 오늘날 이러한 접근방법은 효과적이지 않습니다.이 글에서 제시된 오클루젼 컬링 기술은 렌더러에 통합시키기 아주 간단한 구현을 제공하고, 렌더러에 거의 부담없고GPU에서 오브젝트의 가시성 판별을 전부 결정하여 2가지 이슈를 해결하였다.The algorithm나와 다른 사람이 제시한 다른 많은 GPU 기반 Culling 알고리즘의 경우, Hierarchical-Z 기반 오클루젼 컬링은지오메트리쉐이더의 기능을 사용하여 최종 렌더링에서 보이지 않는 Primitive의 생성을 거부합니다. 이 쉐이더는 오브젝트들의 보이는 데이터들만 제출하며, 이 데이터는 Transform feedback 을 사용하여 buffer object로 출력됩니다.알고리즘 그자체는 현재 GPU에서 구현되어있는 Hierarchical Z-testing 과 유사합니다. 모든 오클루더들을 씬에 렌더링 한후, 우리는 hierarchical depth image를 depth buffer 로 부터 구성합니다. 우리는 이것을 Hi-Z map이라 합니다. 이 텍스쳐맵은 스크린 해상도 사이즈의 밉맵이며, mip level i 의 각각의 텍셀은 mip level i-1에 상응하는 최대 깊이 값을 포함합니다. 이 깊이 정보는 메인 렌더링 패스에서 Occluding objects 들에게서 수집될 수 있다, 왜냐하면 동일한 해상도이기 때문에 별도의 depth pass를 분리할 필요가 없다. 이것은 OpenGL framebuffer objects를 통해 얻어질 수 있다.Hi-Z 맵을 구성한 후, 오클루젼 컬링은 오브젝트 바운드 볼륨의 depth value와 Hi-Z map의 depth 정보를 비교함으로써 수행될 수 있다. Hi-Z map의 Hierarchical 밉맵 구조는 편리합니다. 왜냐하면 우리가 전통적인 depth 비교를 적은 수의 texture fetch를 특정 mip-level에서 직접 샘플링하기 때문입니다.이것이 왜 우리가 Hi-Z map을 "최대 depth 값 저장' 정책으로 구성한 이유입니다. 이것은 일반적인 depth buffer 비교 설정인 Greater or GEqual 중 하나와 동작될 것입니다. 반대 방향의 depth buffer는 '최소 depth 값 저장' 정책을 사용해야 합니다.Hi-Z map constructionsingle-sample rendering의 경우, Scene을 렌더링하기 위해서 메인 depth buffer를 Hi-Z 로 사용할 수 있습니다.이 기술은 multi-sample rendering 으로 확장되지만 이경우 분리된 full-screen quad pass가 필요합니다. 왜냐하면멀티샘플된 depth buffer의 각각의 sample들의 최대 depth 값을 계산하고 싱글샘플된 Hi-Z map 으로 저장해야하기 때문입니다. 이것은 OpenGL3.2 나 ARB_texture_multisample 확장을 사용하면 가능합니다. 추가적인 단계 외에는 알고리즘은 동일합니다.Hi-Z map은 OpenGL framebuffer 오브젝트들에 full-screen quad pass를 각각의 mip-level 레벨을 렌더링하여 구성합니다. 각각의 밉맵레벨은 이전 밉맵을 입력텍스쳐로 그리고 현재 밉맵 레벨을 렌더타겟으로 설정합니다. OpenGL은 같은 mip-level에 접근하지 않는 이상 같은 텍스쳐 오브젝트에 접근하여 읽기와 쓰기가 가능합니다. 알고리즘은 아래와 같습니다.
// bind depth texture
glBindTexture(GL_TEXTURE_2D, depthTexture);
// calculate the number of mipmap levels for NPOT texture
int numLevels = 1 + (int)floorf(log2f(fmaxf(SCREEN_WIDTH, SCREEN_HEIGHT)));
int currentWidth = SCREEN_WIDTH;
int currentHeight = SCREEN_HEIGHT;
for (int i=1; i<numLevels; i++) {
// calculate next viewport size
currentWidth /= 2;
currentHeight /= 2;
// ensure that the viewport size is always at least 1x1
currentWidth = currentWidth > 0 ? currentWidth : 1;
currentHeight = currentHeight > 0 ? currentHeight : 1;
glViewport(0, 0, currentWidth, currentHeight);
// bind next level for rendering but first restrict fetches only to previous level
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_BASE_LEVEL, i-1);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAX_LEVEL, i-1);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT,
GL_TEXTURE_2D, depthTexture, i);
// draw full-screen quad
............
}
// reset mipmap level range for the depth image
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_BASE_LEVEL, 0);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAX_LEVEL, numLevels-1);
반올림 문제로 인해 NPOT(Non-power-of-two) 텍스쳐의 경우 뷰포트 크기가 항상 적어 1x1 이상이 되도록 하는 것을 잊지 않아야 한다. 나는 이것을 처음에 잊어버려서 마지막 mip-level이 채워지지 않는 것을 한시간 정도 해매었다.아마 이 기술이 너무 많은 full-screen quad pass를 후에도 효율적일 수 있을지 궁금할 수 있는데, 그것은 실제로 아주 효율적이고 RADEON HD5770 에서 Hi-Z map을 구성하는데 0.2ms 보다 적게 걸렸다. 나는 OpenGL timer queries( ARB_timer_query 를 보세요)를 사용했기때문에 측정치는 아주 정확할 것이다.Hi-Z map을 구성하는데 사용하는 Fragment Shader는 하나를 제외하면 아주 간단하다. 우리는 윈도우 화면 비율때문에 NPOT depth texture를 사용하는데 NPOT 텍스쳐는 floor 규칙을 다음 mip-level의 크기를 결정하는데 사용한다. (ARB_texture_non_power_of_two 확장 참고) odd-sized mip-level 레벨로 부터 사이즈를 감소시키는 경우 우리는 가장자리 텍셀을 잊으면 안되기 때문에 우리는 예측하여 fetch 하는 것이 필요합니다.
#version 400 core
uniform sampler2D LastMip;
uniform ivec2 LastMipSize;
in vec2 TexCoord;
void main(void)
{
vec4 texels;
texels.x = texture(LastMip, TexCoord).x;
texels.y = textureOffset(LastMip, TexCoord, ivec2(-1, 0)).x;
texels.z = textureOffset(LastMip, TexCoord, ivec2(-1,-1)).x;
texels.w = textureOffset(LastMip, TexCoord, ivec2( 0,-1)).x;
float maxZ = max(max(texels.x, texels.y), max(texels.z, texels.w));
vec3 extra;
// if we are reducing an odd-width texture then fetch the edge texels
if (((LastMipSize.x & 1) != 0) && (int(gl_FragCoord.x) == LastMipSize.x-3))
{
// if both edges are odd, fetch the top-left corner texel
if (((LastMipSize.y & 1) != 0) && (int(gl_FragCoord.y) == LastMipSize.y-3))
{
extra.z = textureOffset(LastMip, TexCoord, ivec2(1, 1)).x;
maxZ = max(maxZ, extra.z);
}
extra.x = textureOffset(LastMip, TexCoord, ivec2(1, 0)).x;
extra.y = textureOffset(LastMip, TexCoord, ivec2(1, -1)).x;
maxZ = max(maxZ, max(extra.x, extra.y));
}
else
{
// if we are reducing an odd-height texture then fetch the edge texels
if (((LastMipSize.y & 1) != 0) && (int(gl_FragCoord.y) == LastMipSize.y-3))
{
extra.x = textureOffset(LastMip, TexCoord, ivec2( 0, 1)).x;
extra.y = textureOffset(LastMip, TexCoord, ivec2(-1, 1)).x;
maxZ = max(maxZ, max(extra.x, extra.y));
}
}
gl_FragDepth = maxZ;
}
나는 texture gathering lookup을 실험하였는데, 텍스쳐 패치를 프래그먼트당 4-to-7에서 1-to-3 (ARB_texture_gather 확장참고) 로 줄이기 위해서였습니다. 텍스쳐 수집은 image가 linearly sampled 일때만 동작하였습니다. 그래서 렌더링 하는동안 추가적인 비용(필터링 스테이트 변경과 관련된)을 피하기 위해서 나는 간단한 texture lookup만 고집했습니다. 왜냐하면 texture gather lookup을 하는 것이 Hi-Z map의 구성하는데 어떤한 효과도 보여주지 못하였기 때문입니다.
Hi-Z map의 다양한 mip-level. Hi-Z map 크기는 1024x768 그림에 있는 mip-level은 level 4(left), level 5(middle) 그리고 level 6(right)
디버깅과 시연을 목적으로 Mountain 데모는 내장된 함수가 다양한 Hi-Z map의 mip-level의 내용을 표시하기 위해 있습니다. 이것은 Hi-Z map 기반 오클루젼 컬링이 켜져있을때, F2 키를 누르면 사용가능 합니다. +와 -키로 mip-level을 변경할 수 있습니다.더 나은 depth buffer의 depth 정보 표시를 위해서, 나는 depth texture의 non-linear depth values를 linear depth value로 변환시켰습니다. [GeeXLab] How to Visualize the Depth Buffer in GLSL.Culling with the Hi-Z mapHi-Z map이 구성되어 지면, 우리는 가시성이 결정된 오브젝트의 바운드볼륨이 차지하는 스크린영역에 상응하는 2x2 이웃 텍셀을 fetch 함으로 써 오클루젼 컬링을 수행할 수 있습니다. 데모에서, 나는 바운딩 박스를 사용했으나 다른 어떠한 볼륨도 사용가능합니다. (즉, 바운딩 스피어는 보통 이 기술에 충분함)첫째로, 우리는 clip space 바운딩 볼륨의 바운드 사각형을 계산해야 합니다. 바운딩 박스의 경우 바운딩 박스의 vertex들을 clip space로 변환하므로써 완료되어질 수 있습니다. 그리고나서 최소와 최대 X, Y 좌표를 계산합니다. 이 바운딩 사각형은 2가지에 사용됩니다. : Hi-Z lookup 에 사용되는 텍스쳐좌표를 정의하고 texture lookup을 할 적절한 LOD를 결정하게 합니다.우리가 fetch를 할 텍스쳐 LOD를 결정하기 위해서 우리는 이전에 결정한 clip space 바운드 사각형에 해당하는 바운딩 정사각형의 screen space 크기를 계산해야만 합니다. 이것은 clip space의 바운드 사각형의 가로크기와 세로크기로 계산 될수 있으며 그리고나서 이것을 screen space로 변환합니다.
float ViewSizeX = (BoundingRect[1].x-BoundingRect[0].x) * Transform.Viewport.y;
float ViewSizeY = (BoundingRect[1].y-BoundingRect[0].y) * Transform.Viewport.z;
(역주 : 위의 Transform.Viewport.y, Transform.Viewport.z는
각각 Transform.Viewport.z, Transform.Viewport.w 로 변경되어야 할것 같습니다.
실제 코드에 Viewport의 사이즈 z, w 컴포넌트에 들어있습니다.
float ViewSizeX = (BoundingRect[1].x-BoundingRect[0].x) * Transform.Viewport.z;
float ViewSizeY = (BoundingRect[1].y-BoundingRect[0].y) * Transform.Viewport.w;
)
이것 후에, 아래의 공식으로 Texture LOD를 얻을 수 있습니다.
float LOD = ceil(log2(max(ViewSizeX, ViewSizeY) / 2.0));
마지막으로 텍스쳐 좌표계와 LOD가 있으므로(clip space 바운딩 사각형의 vertices), 우리는 4개의 texture lookup을 이 파라메터들을 사용해 Hi-Z map에 보내면됩니다. 그리고 반환된 4개의 depth value 중 최대값을 계산하고 오브젝트의 depth value와 비교합니다.(오브젝트의 가장 앞쪽에 있는 depth value로 이것 역시 바운딩 박스의 clip space 좌표로 부터 얻는다) 만약 오브젝트 depth가 참조깊이 보다 크면, 오브젝트는 가려집니다. 그래서 geometry shader에 의해 컬링됩니다.궁금할 수 있는 부분이 우리가 왜 2x2 texel 영역을 참조깊이값을 계산하는데 사용하는가? 왜 그냥 다음 mip-level에서 한번만 fetch하지 않는가? 이다. (왜냐하면 Hi-Z map 생성 방식 때문에 거기에도 2x2 texel 영역의 최대값을 얻을 수 있기 때문) 이것은 나또한 나 자신에게 질문했던 것이었지만 빠르게 이유를 알아냈다.
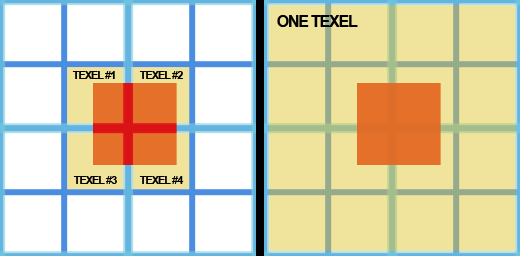
오클루젼 컬링에 사용된 fetch 수 비교. 두 그림은 확대된 mip-level N의 single Hi-Z map texel의 screen coverage를 보여준다. mip-level N-1 texel coverage 는 청록 그리고 N-2는 파랑색이다. 오브젝트는 빨강 그리고 노랑은 fetch 된 텍스쳐이다.